

查找没有链接的网页很困难,但并非没有可能。
如果您的网站上有用户和搜索引擎无法访问的页面,则需要解决此问题。
快速。
这些类型的页面有一个名称:孤立页面。
在这篇文章中,您将了解什么是孤立页面,为何修复它们对于google seo至关重要,以及如何查找网站上的每个孤立页面。
什么是孤立页面?
没有任何链接的页面称为孤立页面。
像Google这样的搜索引擎通常以以下两种方式之一查找新页面:
- 搜寻器会跟踪另一个页面上的链接。
- 搜寻器会找到XML站点地图中列出的URL 。
因此,如果您希望Google 抓取您的页面并将其编入索引,则他们必须能够找到它。
为什么孤立页面是SEO问题?
搜索引擎无法通过链接找到孤立页面,因此孤立页面通常没有索引,也永远不会出现在搜索结果中。
即使您的孤立页面列在XML站点地图中,对于谷歌SEO仍然是一个问题。
孤儿页面不好吗?
孤立页面对用户或搜寻器都不适用。
用户无法通过您网站的自然结构访问这些页面,因此,如果这些页面上有重要或有用的信息,那将是浪费。
这会造成令人沮丧的用户体验。
没有内部链接,没有权限传递给页面,搜索引擎也没有语义或结构性上下文来评估页面。
如果不知道页面整体适合您的网站的位置,那么确定该页面与哪些查询相关就更加困难。
孤儿vs死角页面
在深入研究孤立页面之前,让我们花一点时间来简要阐明两个SEO术语之间 可能引起混淆的区别 。
正如我们已经建立的那样,孤立页面是指与同一网站上的任何其他页面均未链接或无法访问的网页。
另一方面,死胡同页面是没有链接到任何其他内部网页或任何外部网站的网页,因此造成“死胡同”。
当人们登陆该页面时,他们可以回击或放弃该站点。
当搜索引擎爬网程序降落在页面上时,它们无处可去,并且无法传递链接所有权。
如今,有了如此多的模板和主题,创建死胡同更加困难,但几乎是不可能的。
通过向页面内容添加链接,或确保在每个页面上都填充了侧边栏或页脚导航,可以轻松地解决死胡同。
现在,让我们找到您的孤立页面。
1.识别您的可抓取页面
您将需要通过爬网站点的链接来获得当前可以访问的所有URL的列表。
为此,您将需要自己的搜寻器-SEO蜘蛛。ScreamingFrog是一个不错的选择。
无论使用哪种搜寻器,请确保将其设置为仅搜寻可被搜索引擎索引的页面。
那样的话,我的意思是它不应抓取以下页面:
- 没有索引
- 被robots.txt隐藏在搜索引擎中。
从网站的首页开始抓取。
确保使用规范的URL,包括正确的https或http,以及www或非www。
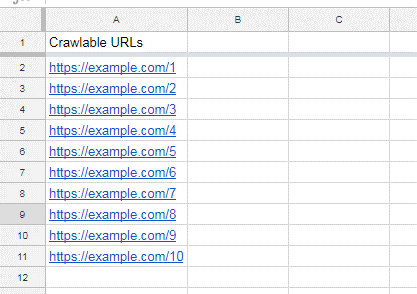
抓取您的网站后,将URL导出到电子表格,如下所示:
2.解决导致孤立页面的2个常见原因
有两种常见的孤立页面原因,应立即解决并解决。
这两个原因本质上都是页面重复,应该自动一致地重定向到仅一个URL。
如果不这样做,则可能是页面的某些版本未链接到,因此是孤立的。
在这种情况下,不是孤儿的事实不是主要问题,而是重复的事实。
这些可能稍后会在您查找孤立页面时出现,并且需要进行处理,因此,**先将它们移开。
非规范的https / http或www / non-www
理想情况下,您网站上的每个公共页面都应一致使用http或https(**是https),以及一致使用www或非www。
要检查这种情况,请尝试在浏览器中键入网站首页的所有这些变体:
- https://www.example.com
- http://www.example.com
- https://example.com
- http://example.com
所有四个变体应自动重定向到完全相同的URL。
为了保持一致,该页面应具有规范性。
如果这些变体之一无法正确重定向,则可能是更广泛站点上出现类似问题的迹象。
使用该变体检查其他URL,以查看是否是更普遍的问题。
您应该测试站点的其他几个页面,并检查站点的.htaccess文件,以确保正确设置了这些页面的重定向。
这是在.htaccess中强制使用https的方法。如果这样做,请确认您站点上的每个页面都具有SSL功能,否则您的用户将收到可怕的浏览器警告。
这是强制www或非www的方法。再次,确认这不会造成任何服务器错误。
尾部斜杠
要注意的另一件事是始终使用尾部斜杠。
例如,这两个URL可能产生相同的内容,但是URL 不相同:
- https://example.com/page1/
- https://example.com/page1
检查您网站上的几个页面是否带有斜杠,并确保它们自动重定向到相同的URL,并且始终如一。
验证是否已在.htaccess中正确设置。
这是在.htaccess中强制使用斜杠的方法。
3.识别您的孤立URL
要识别我们的孤立网址,我们需要比较可抓取网址列表和电子表格中找到的Google Analytics(分析)URL列表。
在我们的假设示例中,很明显https://example.com/11是一个孤立页面,但实际上,您几乎总是会有更多的URL可供浏览,我们将需要自动执行识别孤立URL的过程。
为此,我们需要一个公式来检查Google Analytics(分析)列表中的每个URL 是否也在我们的Crawlable URLs列表中找到。
这是将完成此任务的公式的示例:
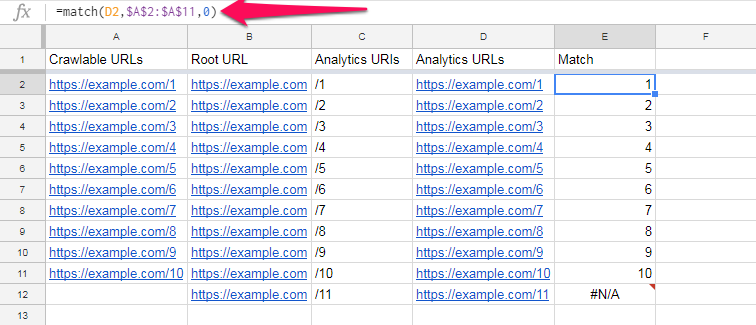
我们在单元格E2中使用的“匹配”公式为:
=匹配(D2,$ A $ 2:$ A $ 11,0)
此公式检查单元格D2中的URL是否在$ A $ 2:$ A $ 11范围内。
(如果您不太熟悉电子表格,则可以使用美元符号来确保当我们将公式向下拖动到列中时,范围不会改变。)
值“ 0”表示Google表格无需对列进行排序。(请参阅Google表格文档。)
如果存在匹配项,则公式将返回其在范围内的位置,在这种情况下,该位置是该范围内的第一个位置。
但是,我们更感兴趣的是没有比赛。
如您所见,该公式对于https://example.com/11返回错误“ #N / A”,因为在我们的“可抓取的网址”列表中找不到该错误。这意味着它是一个孤立页面。
要获取我们的孤儿页面列表,我们要做的就是对“ 匹配”列进行排序,以将所有“#N / A”结果收集到一个位置。
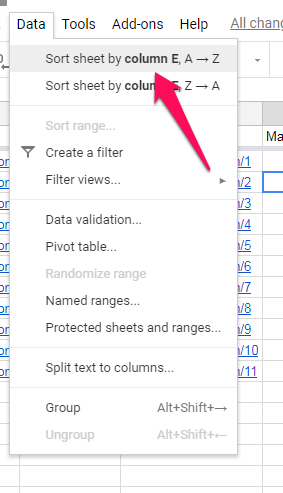
然后,我们可以复制孤立URL列表并将其粘贴到新的工作表中,在这里我们可以解决如何解决它们。
结论:查找和修复孤立页面
如果孤立页面没有出现在您的站点地图中,它们将无法被搜索引擎索引–并且它们可以创建其他SEO问题。
完成这些步骤并找到孤立页面后,请问自己一些问题:
- 此页面重要吗?如果是这样,找到在哪里集成它。如果没有,请将其删除。
- 尽管该页面是孤立页面,但该页面是否对任何关键字排名?如果是这样,找到在哪里集成它。如果没有,请将其删除。
- 该页面应在您网站的分类法中的什么位置?
- 此页面是重复的还是几乎重复的?考虑将内容折叠到非孤立的相似页面中。
- 此页面是否经过优化?是否可以对其进行优化和更好地链接?
- 页面是否已从外部来源链接到?
使用本文中概述的方法来查找您的孤立页面,并解决此问题。
- 本文由上海上弦发布,不代表上海上弦立场,转载联系作者并注明出处:https://www.sun.sh.cn/find-orphan-page
